
Kernidee
In dieser Unterrichtsreihe geht es darum Schülerinnen und Schülern (SuS) eine Vorstellung von maschinellem Lernen und Künstlicher Intelligenz zu vermitteln. Dies wird anhand von datenbasierten Entscheidungsbäumen erarbeitet. Die Umsetzung in dieser Reihe basiert hauptsächlich auf unplugged Materialien, die das handlungsorientierte Lernen auf enaktiver Ebene ermöglichen. Dies wird ergänzt durch eine digitale Lernumgebung, die zum Ende der Reihe flexibel einsetzbar ist. Der ausgewählte Kontext „Lebensmittel“ ist für alle SuS relevant und insbesondere auch für jüngere SuS geeignet.
Lebensmittel kann man anhand von Nährwertangaben als “eher empfehlenswert” oder “eher nicht empfehlenswert” klassifizieren. Dabei müssen mehrere Merkmale wie Fettgehalt, Zuckergehalt und Kalorien berücksichtigt werden. Ein mehrstufiges Regelsystem, mit dem solche Klassifikationen durchgeführt werden können, sind sogenannte Entscheidungsbäume (engl. decision trees). Solche Entscheidungsbäume kann man basierend auf Daten erstellen. Mit Daten ist hier gemeint: Man geht von einer Menge von Lebensmitteln aus, zu dem Nährwertangaben bekannt sind, und zu denen man weiß, ob sie eher empfehlenswert oder nicht empfehlenswert sind. Darauf aufbauend kann man “manuell” schrittweise Entscheidungsbäume erstellen, die die Lebensmittel zunehmend fehlerfreier klassifizieren. Dieser Erstellungsprozess kann auch automatisiert werden, um nach bestimmten Kriterien optimale Entscheidungsregeln zu finden. Die Automatisierung erfordert, jedes Lebensmittel als “Datenkarte” – das ist eine Liste von Zahlenwerten zu den verschiedenen Nährwertmerkmalen – digital zu repräsentieren. Ein maschinelles Lernverfahren entwickelt zu diesen Daten einen passenden (daten-basierten) Entscheidungsbaum. In der Praxis sind neben Entscheidungsbäumen auch andere Typen von Klassifikatoren – z.B. neuronale Netze – im Gebrauch, mit darauf angepassten maschinellen Lernverfahren.
Entscheidungsbäume haben den Vorteil, dass sie als Regelsystem von SuS verstanden werden können, ebenso können die Erstellungsverfahren eines Baumes zunächst manuell erarbeitet und dann am Computer automatisiert werden. Im Unterricht werden Lebensmittel zunächst als reale Datenkarten modellhaft repräsentiert und die SuS können Karten sortieren und klassifizieren, um sich auf einer enaktiven Ebene Verfahren anzueignen. Der Anspruch ist, einen Einblick “in den Maschinenraum” des maschinellen Lernens zu gewinnen und nicht nur vorgegebene Systeme, die eine völlige Black-Box bleiben, als Klassifikatoren mit Daten zu trainieren.
In dieser Unterrichtsreihe wird in ca. 9 Unterrichtsstunden in datenbasierte Entscheidungsbäume eingeführt. Dabei steht im Vordergrund, wie ein Entscheidungsbaum aufgebaut ist und wie die passenden Entscheidungsregeln datenbasiert hergeleitet werden. Dieser systematische, datenbasierte Erstellungsprozess kann dann als eine Methode des maschinellen Lernens automatisiert erfolgen und ein resultierender Entscheidungsbaum kann als eine Form künstlicher Intelligenz bezeichnet werden. Dazu erstellen SuS manuell mit Hilfe von Datenkarten eigene Entscheidungsbäume, um zu verstehen, erstens wie ein Entscheidungsbaum als Regelsystem aufgebaut ist, und zweitens wie man systematisch bei der Konstruktion vorgehen kann, um Entscheidungsbäume mit möglichst geringer Fehlklassifikationsanzahl zu erhalten. Ergänzend gibt es eine vorbereitete digitale Lernumgebung, in der SuS Entscheidungsbäume automatisiert erstellen können. Dabei lernen sie etwas über Künstliche Intelligenz und maschinelles Lernen. Sie lernen Entscheidungsbäume als gewinnbringende Repräsentation von Daten kennen, mit deren Hilfe Erkenntnisse gewonnen und Vorhersagen getroffen werden können, bei deren Anwendung aber auch Fehler passieren können.
Auf fachlicher Basis der deutschen Gesellschaft für Ernährung (DGE) wird das Thema Ernährung aufgegriffen, welches in der Sekundarstufe I behandelt werden sollte, aber aktuell in den Lehrplänen der verschiedenen Fächer unterrepräsentiert ist. Auf diese Weise wird das Thema maschinelles Lernen mit einem bildungsrelevanten Sachthema verknüpft. Der Kontext ist nicht typische für den Bereich KI und maschinelles Lernen, eignet sich aber für die Anbindung an die Erfahrungswelt aller SuS (unabhängig von Alter, Geschlecht, etc.). Es gibt dazu Verknüpfungsmöglichkeiten z. B. zum Biologieunterricht und die Behandlung des Kontextes kann einen Beitrag zu allgemeinbildendem Unterricht darstellen.
Zielgruppe
Informatik in Klasse 5 und 6 (alle Schulformen) – Anknüpfung an Biologie- und Mathematikunterricht möglich.
Empfehlung: Ab Klasse 6
Inhaltsfeld
“Künstliche Intelligenz und maschinelles Lernen” (insbesondere der Schwerpunkt: überwachtes Lernen mit Entscheidungsbäumen), “Daten und Information”
Vorkenntnisse
Basiskenntnisse über Nährwertangaben sind wünschenswert, entsprechende Erklärungen könnten aber auch in diesem Modul integriert werden
Zeitlicher Umfang
8 bis 10 Unterrichtsstunden a 45 Minuten
Ziele
Bezogen auf Datenkarten Entscheidungsbäume:
Die SuS…
- können einen Entscheidungsbaum als Regelsystem zum Klassifizieren von Objekten anwenden.
- verstehen eine Datenkarte als Repräsentation eines Objekts, auf dem die Ausprägungen verschiedener Merkmale dieses Objekts erfasst sind.
- erstellen Entscheidungsregeln zum Klassifizieren von Objekten hinsichtlich eines (Ziel-)Merkmals systematisch basierend auf Daten (in Form einer Sammlung von Datenkarten), d. h. basierend auf den Ausprägungen anderer (Prädiktor-)Merkmale der Objekte.
- präsentieren und reflektieren eigene Entscheidungsbäume angemessen.
- verstehen die Rolle von Daten als Grundlage für die Erstellung von Entscheidungsbäumen.
- verstehen, dass Entscheidungsbäume Prognosen liefern sollen (Klassifikationen neuer Objekte) und deshalb mit neuen Daten getestet werden müssen und dass dabei Fehler in Form falscher Prognosen auftreten können.
- bewerten Entscheidungsbäume anhand der Anzahl falsch klassifizierter Objekte in einem Datensatz.
- beschreiben anhand ihrer manuellen Erfahrungen mit Datenkarten, wie ein Computer Entscheidungsbäume automatisiert erstellen kann und identifizieren diesen Vorgang als maschinelles Lernen.
Bezogen auf den Inhalt Lebensmittel:
Die SuS…
- lernen die Bedeutung einzelner Nährwertangaben (Merkmale) bei Lebensmitteln und ihre Relevanz für die Qualitätsbewertung von Lebensmitteln kennen.
- leiten aus den gegebenen Nährwertdaten ein Regelsystem ab, das Prognosen darüber trifft , ob ein (neues) Lebensmittel eher empfehlenswert oder eher nicht empfehlenswert ist.
Leitfragen
- Wie kann man anhand der Nährwertangaben einen Entscheidungsbaum konstruieren, der die Beurteilung unterstützt, ob ein Lebensmittel eher empfehlenswert oder eher nicht empfehlenswert ist?
- Wie kann man einen Entscheidungsbaum für dieses Problem automatisiert (durch maschinelles Lernen) erstellen lassen?
Unterrichtsverlauf
Teil 1: Einführung in den Kontext KI und Problematisierung
| Phase | Inhalt | Material | |
|---|---|---|---|
|
1 |
|
Teil 2: Exkurs: Lebensmittel und empfehlenswerte Ernährung (optional)
| Phase | Inhalt | Material | |
|---|---|---|---|
|
2 |
|
Teil 3: Vorbereiten der Daten: Datenkarten mit Labeln versehen
| Phase | Inhalt | Material | |
|---|---|---|---|
|
3 |
|
Teil 4: Einführen des Datenbegriffs und datenbasierter Entscheidungsregeln
| Phase | Inhalt | Material | |
|---|---|---|---|
|
4 |
|
Teil 5: Erstellen guter einstufiger Entscheidungsbäume
| Phase | Inhalt | Material | |
|---|---|---|---|
|
5 |
|
Teil 6: Mehrstufige Entscheidungsbäume erstellen
| Phase | Inhalt | Material | |
|---|---|---|---|
|
6 |
|
Teil 7: Benutzen verschiedener Entscheidungsbäume zum Klassifizieren einer neuen Lebensmittelkarte
| Phase | Inhalt | Material | |
|---|---|---|---|
|
7 |
|
Teil 8: Systematisches Testen von Entscheidungsbäumen anhand mehrerer Testkarten
| Phase | Inhalt | Material | |
|---|---|---|---|
|
8 |
|
Teil 9: Automatisches Erstellen von Entscheidungsbäumen mit dem Computer und Reflexion über Einsatzmöglichkeiten und Grenzen
| Phase | Inhalt | Material | |
|---|---|---|---|
|
9 |
|
Evaluation
| Phase | Inhalt | Material | |
|---|---|---|---|
|
|
|
Glossar
Ast Ein Ast innerhalb eines Entscheidungsbaums ist eine von mehreren Abzweigungen, die von einem Regelknoten zu einem nächsten Knoten führt.
Ausprägung/Merkmalsausprägung Die Werte, die ein Merkmal annehmen kann, nennt man Merkmalsausprägung.
Beispiel (im Kontext von KI) Ein Beispiel ist ein Objekt (z. B. Lebensmittel), das durch bestimmte Merkmale (z. B. Nährstoffe) beschrieben wird und mit einem Label (z. B. „eher empfehlenswert“ oder „eher nicht empfehlenswert“) versehen ist.
Blattknoten Ein Entscheidungsbaum besteht aus verschiedenen Knoten. Die Knoten am Ende eines Entscheidungsbaums nennt man Blattknoten und in ihnen ist immer eine Entscheidung für eine Ausprägung des Zielmerkmals eingetragen.
Datenkarte Eine Datenkarte repräsentiert ein Objekt, indem darauf die Ausprägungen einer Liste von Merkmalen dargestellt sind (z. B. ein Lebensmittel durch Nährwertangaben zu einer Liste von Nährstoffen). Eine Datenkarte kann digital oder analog repräsentiert sein.
Datensplit Ein Datensplit ist die Aufteilung von Daten in Teildatensätze basierend auf den Ausprägungen eines Merkmals, z. B. durch einen Schwellenwert.
Entscheidungsbaum Ein Entscheidungsbaum ist ein (übersichtliches, in gewissen Grenzen nachvollziehbares) Regelsystem, das als Baumdiagramm dargestellt werden kann. Ein solcher Entscheidungsbaum veranschaulicht hierarchisch aufeinanderfolgende Entscheidungsregeln, an deren Ende immer eine Entscheidung für eine bestimmte Fragestellung steht.
Fehlklassifikation Eine Objekt, das durch einen Klassifikator einer falschen Klasse zugeordnet wird nennt man Fehlklassifikation.
Klasse (im Kontext von KI) Eine Klasse ist eine Ausprägung eines kategorialen Zielmerkmals beim überwachten maschinellen Lernen.
Klassifikation Mit einem Entscheidungsbaum kann man Ausprägungen eines (mit einer gewissen Wahrscheinlichkeit) Merkmals vorhersagen. Anders formuliert kann man also ein Objekt einer Klasse zuordnen. Eine solche regelgeleitete Zuordnung zu einer Klasse nennt man Klassifikation.
Klassifikator Ein Klassifikator ist ein Regelsystem (z. B. Entscheidungsbaum), das bestimmte Objekte anahand von Prädiktormerkmalen klassifizieren kann.
Klassifizieren Das Klassifizieren eines Objekts entspricht dem Zuordnen eines Objekts zu einer Klasse (aus einer Menge möglicher Klassen). Klassen können auch als Merkmalsausprägungen eines kategorialen Merkmals verstanden werden.
Künstliche Intelligenz (KI) Künstlicher Intelligenz befasst sich mit der Frage, wie man Computer dazu bringen kann, Dinge zu tun, die Menschen bisher besser beherrschen. Dazu gehören verschiedenste Anwendungen, u. A. die Fähigkeit in verschiedenen Szenarios Vorhersagen zu treffen oder Klassifikationen vorzunehmen die mit einer hohen Rate korrekt sind. Somit zählen leistungsfähige Klassifikatoren (z.B. Entscheidungsbäume) zu den Anwendungen von Künstlicher Intelligenz.
Label Ein Label gibt die Klassenzugehörigkeit eines Objekts an. Das Label kann als Ausprägung eines Merkmals (Zielmerkmal) verstanden werden.
Maschinelles Lernen Maschinelles Lernen bezeichnet Verfahren, in denen eine Lernaufgabe automatisiert durch Lernalgorithmen basierend auf Daten gelöst wird. Maschinelles Lernen unterscheidet verschiedene Arten von Lernaufgaben. Typischerweise wird zwischen drei Arten von Lernaufgaben unterschieden: überwachtes Lernen, unüberwachte Lernen und bestärkendes Lernen. Beim überwachten Lernen geht es darum, die Ausprägung eines Zielmerkmals für eine bestimmte Art von Objekten vorherzusagen. Beim unüberwachten Lernen geht es darum, Objekte anhand bestimmter Merkmale in Gruppen ähnlicher Objekte zusammenzufassen und beim bestärkenden Lernen geht es darum, sogenannte „Agenten“ (z.B. Roboter) zum Handeln zu bringen. Bei allen Lernaufgaben kommen unterschiedlichste Lernalgorithmen zum Einsatz.
Merkmal Merkmale charakterisieren Objekte und können verschiedene Ausprägungen annehmen. Es gibt numerische und kategoriale Merkmale.
Objekt Objekte sind Merkmalsträger jeglicher Art. D. h. Objekte können durch Merkmale beschrieben werden (Z. B. Lebensmittel werden durch Nährwerte beschrieben, Menschen durch charakterisierende Eigenschaften wie Haarfarbe oder Körpergröße). Dabei ist nicht festgelegt welche Merkmale zum beschreiben eines Objektes herangezogen werden.
Pfad Ein Pfad innerhalb eines Entscheidungsbaums ist eine Abfolge von Ästen, die im Wurzelknoten beginnt und in einem Blattknoten endet.
Prädiktormerkmal Beim überwachten maschinellen Lernen geht es darum für eine bestimmte Art von Objekten die Ausprägung eines Zielmerkmals vorherzusagen. Für die Vorhersage wird ein Regelsystem basierend auf weiteren Merkmalen erstellt. Diese weiteren Merkmale, auf denen also die Vorhersage beruht nennt man Prädiktormerkmale.
Regelknoten Ein Entscheidungsbaum besteht aus verschiedenen Knoten. Zu Beginn stehen immer Regelknoten, die anhand von Prädiktormerkmalen gebildete Entscheidungsregeln repräsentieren. Alle Knoten in einem Entscheidungsbaum, bis auf die jeweils letzten Knoten weines Pfades, sind Regelknoten.
Schwellenwert Ein Schwellenwert ist eine Ausprägung, die zu einem numerischen Merkmal gewählt werden kann, um Objekte in Teildatensätze zu gruppieren. Die Teildatensätze ergeben sich aus den Objekten, deren jeweilige Ausprägung kleiner oder gleich dem Schwellenwert ist und denjenigen, deren jeweilige Ausprägung größer als der Schwellenwert ist.
Trainingsdaten Trainingsdaten sind ein Satz von Daten, die genutzt werden, um mit Hilfe von maschinellem Lernen einen Klassifikator (z. B. Entscheidungsbaum) zu erstellen.
Testdaten Testdaten sind ein weiterer Satz von Daten, mit denen ein erstellter KLassifikator getestet wird. Trainings- und Testdaten sind disjunkt.
Zielmerkmal Beim überwachten maschinellen Lernen geht es darum für eine bestimmte Art von Objekten die Ausprägung eines Merkmals vorherzusagen. Das betreffende Merkmal nennt man Zielmerkmal.
Überwachtes maschinelles Lernen (engl.: supervised learning) Überwachtes maschinelles Lernen wird angewandt, um Entscheidungsmodelle zu erstellen, die für eine bestimmte Art von Objekten vorhersagen über ein Zielmerkmal treffen zu können. (z.B. Klassifizieren von Lebensmitteln als “eher empfehlenswert” und “eher nicht empfehlenswert”). Damit das überwachte Lernen angewandt werden kann, benötigt man zuerst digitale Repräsentationen von Objekten, worin die Objekte anhand bestimmer (Prädiktor-)Merkmale beschrieben sind (z. B. Lebensmittel, die durch Nährwertangaben repräsentiert sind). Zusätzlich müssen für alle Objekte die gewünschten Ausprägungen des Zielmerkmals (z.B. eher empfehlenswert/eher nicht empfehlenswert) bekannt sein. Eine Sammlung von Beispielobjekten, denen Werte von Prädiktormerkmalen und Labeln zugeordnet werden, werden so zu einem Satz von Daten, der modellhaft eine ganze Klasse an Objekten repräsentiert. Mit diesen Daten können mit Hilfe von Lernalgorithmen verschiedene Arten von Regelsystemen/Entscheidungsmodellen (z.B. Entscheidungsbaum, neuronales Netz) erstellt werden. Den Erstellungprozess nennt man auch “Lernprozess” oder “Trainingsprozess” und die Daten, die dafür genutzt werden, nennt man Trainingsdaten. Das Verarbeiten der Daten in diesem gesamten Trainingsprozess kann man als “überwachtes maschinelles Lernen” bezeichnen und dabei wird das Regelsystem immer besser an die vorliegenden Daten angepasst, bis am Ende möglichst wenig Fehler bei der Zuordnung (Fehlklassifikationen) passieren. Im ersten Schritt wird ein Entscheidungsmodell also so trainiert, dass es die Trainingsdaten korrekt zuordnet. Zielstellung ist es aber eigentlich, dass das Entscheidungsmodell über die Trainingsdaten hinaus funktioniert und auch neue Objekte (z.B. neue Lebensmittel) korrekt zuordnet. Im Anschluss wird das Entscheidungsmodell mit neuen Objekten bzw. Daten getestet und evaluiert. Dann spricht man von Testdaten. Der Begriff „überwacht“ wird in diesem Zusammenhang genutzt, da für alle verwendeten Objekte in den Daten die Ausprägung des Zielmerkmals bekannt ist und daher genau überwacht werden kann, wie gut des erstellte Entscheidungsmodell für die Daten funktioniert. Ein solches gut funktionierendes Entscheidungsmodell kann man als KI bezeichnen.
Lebensmitteldaten als Datenkarten
In der Unterrichtsreihe werden 55 Datenkarten genutzt, die jeweils die typischen sieben Nährwertangaben eines Lebensmittels enthalten, wie z. B. in Abb. 1 für einen Apfel dargestellt. Die Darstellung der Lebensmitteldaten auf Datenkarten wie in Abb. 1 und das Arbeiten mit Daten knüpfen beispielsweise an das Thema Stochastik im Lehrplan NRW für die Erprobungsstufe (Klasse 5 und 6) an. Allerdings werden von Anfang an „multivariate“ Daten, Daten mit mehreren Merkmalen betrachtet, was in fachdidaktischen Vorschlägen schon länger als Bestandteil von Statistical Literacy gefordert wird. Ähnliche Bezüge finden sich auch in anderen Lehrplänen.
Mit den Datenkarten zu Lebensmittelobjekten wird im Unterricht folgende Leitfrage verfolgt:
- Wie kann man mit Hilfe der Datenkarten ein Empfehlungssystem konstruieren, das ein Lebensmittel basierend auf seinen Nährwertangaben möglichst fehlerfrei als eher empfehlenswert oder eher nicht empfehlenswert klassifiziert?

Ein solches Empfehlungssystem bezeichnet man als Klassifikator, da einzelne Objekte (hier Lebensmittel) basierend auf ihren Merkmalen (Nährwertangaben) einer Klasse („eher empfehlenswert“ oder „eher nicht empfehlenswert“) zugeordnet werden, d. h. sie werden klassifiziert. Man bezeichnet das binäre Merkmal ‚Empfehlung‘ als Zielmerkmal und die numerischen Nährwertmerkmale als Prädiktormerkmale.
Ein solcher Klassifikator wird auf der Basis einer Menge von Objekten entwickelt, für die sowohl die Ausprägungen der Prädiktormerkmale als auch des Zielmerkmals bekannt sind. Das sind die sogenannten Trainingsdaten. Ziel ist es aber immer, dass die Empfehlung auch für neue Objekte funktioniert. Zunächst wird das System mit Testdaten getestet, die nicht am Trainingsprozess beteiligt waren, für die aber die Ausprägungen des Zielmerkmals bekannt sind. Man kann damit abschätzen, mit welcher Wahrscheinlichkeit das System neue Objekte mit unbekannter Ausprägung korrekt klassifiziert.
Das Datenbeispiel umfasst 40 blaue Karten zum Erstellen des Empfehlungssystems und 15 gelbe Karten zum Testen. Es werden rote und grüne Büroklammern genutzt, mit denen im Unterricht die konsentierte Ausprägung des Zielmerkmals (auch Label genannt) dargestellt wird. Zum Herstellen eines einheitlich gelabelten Trainingsdatensatzes kann im Unterricht die Ernährungspyramide der Deutschen Gesellschaft für Ernährung (DGE, https://www.dge.de/gesunde-ernaehrung/dge-ernaehrungsempfehlungen/dreidimensionale-dge-lebensmittelpyramide/) genutzt werden.
Ein Entscheidungsbaum als Klassifikator
Im Folgenden wird für Lehrkräfte eingeführt, was ein Entscheidungsbaum ist und wie man einen solchen datenbasiert mit Datenkarten erstellen kann. Auf die unterrichtliche Umsetzung wird erst später eingegangen. Ein Entscheidungsbaum ist ein hierarchisches Regelsystem, das als Klassifikator genutzt werden kann. Ein Beispiel für einen Entscheidungsbaum zum zuvor beschrieben Kontext ist in Abb. 2 dargestellt. Man kann mit diesem Regelsystem z. B. den Apfel aus Abb. 1 klassifizieren, indem man den Entscheidungsbaum von oben nach unten durchläuft und abhängig von den Werten für die Merkmale Fett und Energie die passenden Abzweigungen wählt. Der erste Regelknoten fragt das Merkmal Fett ab. Da der Apfel weniger als 8 g Fett pro 100 g enthält, nimmt man den linken Ast und landet direkt in einem Endknoten (auch Blattknoten) des Entscheidungsbaums. Ein Endknoten enthält als Aufschrift immer eine Ausprägung des Zielmerkmals, die dem zu klassifizierenden Objekt zugeordnet wird. Der Apfel wird dementsprechend als „eher empfehlenswert“ klassifiziert. Bei einem Lebensmittel mit einem Fettwert größer als 8 g müsste man den rechten Ast nehmen und in zweiter Stufe noch den Energiewert betrachten, um in einen Endknoten zu gelangen.
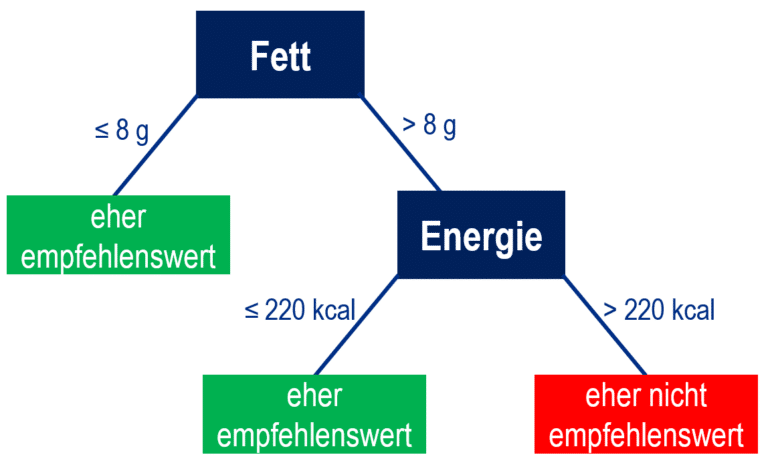
Dieser Entscheidungsbaum ist hier lediglich ein Beispiel ohne den Anspruch, Lebensmittel tatsächlich sinnvoll zu klassifizieren. Prinzipiell kann ein solcher Entscheidungsbaum beliebig viele Stufen und Prädiktormerkmale enthalten. Ziel der Unterrichtsreihe ist, dass Lernende solch einen Entscheidungsbaum datenbasiert selbst erstellen und verstehen, wie Computer so eingerichtet werden können, dass aus den Daten automatisiert Entscheidungsbäume erstellt werden (Maschinelles Lernen als Teil der KI).
Einen Entscheidungsbaum datenbasiert erstellen
Eine Voraussetzung für das datenbasierte Erstellen von Entscheidungsbäumen ist, dass ein Datensatz vorliegt, der aus einer Menge von Beispielobjekten besteht, für die die Ausprägungen des Zielmerkmals und der Prädiktormerkmale bekannt sind. Wir betrachten im Folgenden (Abb. 3 und Abb. 4) beispielhaft elf Lebensmittel als Beispielobjekte, deren Nährwertangaben jeweils auf der Karte angegeben sind. Das sind die Ausprägungen der Prädiktormerkmale Fett, Energie etc. Ferner wird durch eine grüne (bzw. rote) Klammer (als Ausprägung des Zielmerkmals) symbolisiert, ob das Lebensmittel als eher empfehlenswert (bzw. eher nicht empfehlenswert) eingestuft ist. Mit so einer Datengrundlage kann ein Entscheidungsbaum nach und nach aufgebaut werden mit dem Ziel, die Trainingsdaten möglichst fehlerarm zu klassifizieren.
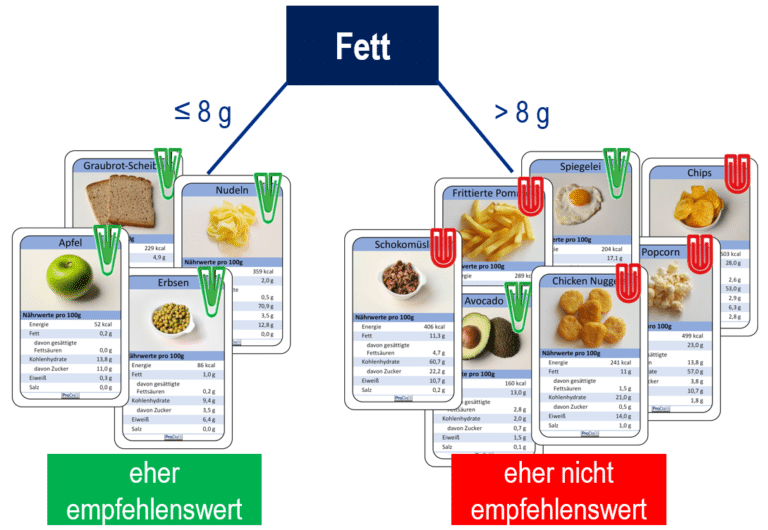
Als Basis für den Erstellungsprozess des Entscheidungsbaums dient der sogenannten Datensplit, d. h. durch ein Prädiktormerkmal und einen Schwellenwert werden zwei Teildatensätze erzeugt (Komponente 1). In Abb. 3 sieht man einen Datensplit mit dem Merkmal Fett und dem Schwellenwert 8 g, d. h. auf der rechten Seite befinden sich alle Lebensmittel mit mehr als 8 g Fett und links mit bis zu 8 g Fett. In beiden Teildatensätzen wird dann eine Mehrheitsentscheidung hinsichtlich des Zielmerkmals gefällt (Komponente 2). Auf der linken Seite in unserem Beispiel sind ausschließlich eher empfehlenswerte Lebensmittel und auf der rechten Seite ist die Mehrheit der Lebensmittel eher nicht empfehlenswert. Die resultierende Entscheidungsregel (wenn ≤ 8 g Fett, dann eher empfehlenswert; wenn > 8 g Fett, dann eher nicht empfehlenswert) kann evaluiert werden (Komponente 3), indem die Anzahl der dadurch im Datensatz falsch klassifizierten Lebensmittel (Fehlklassifikationen) bestimmt wird. In unserem Beispiel sind es zwei Lebensmittel, die falsch klassifiziert werden, nämlich Avocado und Spiegelei auf der rechten Seite. Die Datensplits werden beim Aufbau eines Entscheidungsbaumes so gewählt, dass diese Mehrheitsentscheidungen möglichst wenige Fehlklassifikationen erzeugen. Abschließend kann man den resultierenden einstufigen Entscheidungsbaum repräsentieren (Komponente 4). Dies kann rein verbal geschehen oder durch ein typisches Baumdiagramm. In der Repräsentation des Entscheidungsbaums kommen die Datenkarten nicht mehr vor, aber es sollte statt der Karten (vgl. Abb. 3) die Verteilung des Zielmerkmals in beiden Teildatensätzen (4 zu 0; 2 zu 5) notiert werden, damit die Anzahl der Fehklassifikationen nachvollziehbar ist.
Nun kann man den bisher einstufigen Entscheidungsbaum, der ja zwei Lebensmittel falsch klassifiziert, weiter verbessern, indem man eine weitere Stufe hinzufügt. Die Datenkarten im linken Ast können beiseitegelegt werden, da dort schon alles korrekt klassifiziert wird. Mit den Karten im rechten Ast verfährt man genau wie für die erste Stufe beschrieben. Wenn man das Prädiktormerkmal Energie und den Schwellenwert 220 kcal für einen weiteren Datensplit nutzt, erhält man den Entscheidungsbaum aus Abb. 2, der für dieses Datenbeispiel alle Lebensmittel korrekt klassifiziert.
Ein zentraler Aspekt, der bisher noch nicht erklärt wurde, ist wie ein Merkmal und ein Schwellenwert für einen ersten Datensplit und dann für die weiteren „günstig“, also derart, dass möglichst wenig Fehlklassifikationen auftreten, ausgewählt werden. Mit den Datenkarten kann dies durch Sortieren und systematisches Probieren umgesetzt werden.
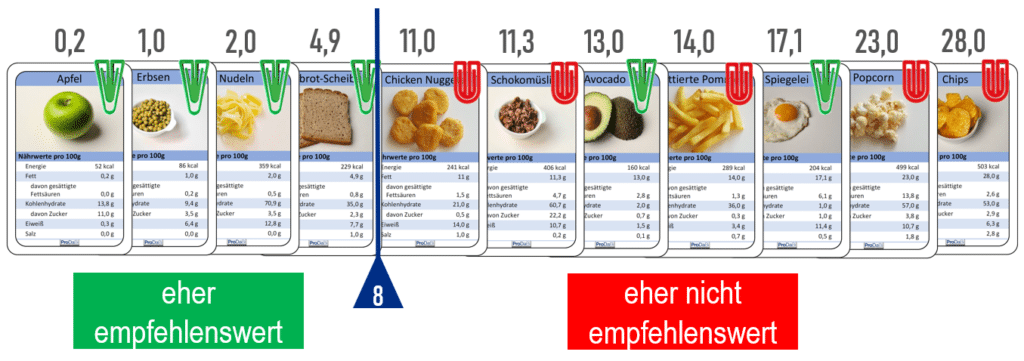
Ausgehend von den sortierten Datenkarten können verschiedene mögliche Datensplits und die resultierende Anzahl von Fehlklassifikationen miteinander verglichen werden. Für ein gegebenes Datenbeispiel betrachten wir denjenigen Datensplit als optimal, der die geringste Anzahl falsch klassifizierter Objekte liefert. In diesem Beispiel ist der optimale Datensplit der in Abb. 4 visualisierte zwischen der Graubrot-Scheibe und den Chicken Nuggets. Dies kann man überprüfen, indem man systematisch alle Datensplits untersucht. Dafür verschiebt man den trennenden senkrechten Strich einmal in alle Zwischenräume zwischen zwei Karten und wendet jeweils die zuvor erläuterten Komponenten 1-3 an, um die Anzahl falsch klassifizierter Objekte zu ermitteln. Ein Datensplit zwischen Avocado und Pommes liefert z. B. drei falsch klassifizierte Objekte und ist somit schlechter zu bewerten.
Wenn ein optimaler Datensplit ausgewählt ist (in unserem Beispiel mit zwei falsch klassifizierten Objekten), kann ein Schwellenwert im Intervall zwischen den Fettwerten der beiden anliegenden Karten gewählt werden. In Abb. 4 wurde im Intervall zwischen den Werten 4,9 und 11,0 der Wert 8 als Schwellenwert gewählt. Für alle anderen Prädiktormerkmale kann dann auch ein optimaler Datensplit bestimmt werden, um anschließend das Prädiktormerkmal auszuwählen, das eine möglichst geringe Anzahl falsch klassifizierter Lebensmittel liefert. Man geht also mit einer sogenannten „Greedy-Strategie“ vor, d. h. man sucht den besten einstufigen Entscheidungsbaum und betrachtet dann erst die zweiten Stufen und entscheidet, ob dort weitere Datensplits nötig sind. Dort wählt man wieder das beste Merkmal mit dem optimalen Datensplit in der betrachteten Teilmenge der Daten. Es ist diese systematische Methode, die im Wesentlichen in den professionellen Entscheidungsbaum-algorithmen implementiert ist. Dazu gehören dann noch geeignete Abbruchkriterien. In der Unterrichtspraxis ist das Einbeziehen aller Datensplits für Lernende sehr mühsam, sodass (zunächst) etwas vereinfachte Strategien, die bei der Beschreibung des Unterrichts im nächsten Abschnitt erläutert werden, verwendet werden können. Diese Strategien folgen dem gleichen Ansatz und können deshalb die Grundlage dafür liefern, zu verstehen, wie eine Maschine automatisiert, vollständig und systematisch vorgeht.
Materialien
Gesammelter Download aller Materialien
Eine Druckvorlage für die Datenkarten finden Sie hier:
Zwei Klassensätze der Datenkarten können Sie hier bestellen:
Zum Teil 1: Aufbau und Funktionsweise des Mobilfunknetzes
- Download: Folien Gedankenexperiment (für Phase 1a)
- Link: Erklärvideo zum Mobilfunknetz (Phase 1b)
- Download: Druckvorlage für das Puzzle (für Phase 1b)
- Download: Arbeitsblatt 1 (für Phase 1b)
- Download: Arbeitsblatt 2 für Niveaustufe 1 (für Phase 1b)
- Download: Arbeitsblatt 2 für Niveaustufe 2 (für Phase 1b)
- Download: Sprinteraufgabe für Arbeitsblatt 2 (für Phase 1b)
- Download: Arbeitsblatt 3 (für Phase 1b)
Zum Teil 3: Exploration gegebener Standortdaten
Weitere Informationen
Lernstrecke für Schüler:innen - Entscheidungsbäume mit Datenkarten
Die Lernstrecke “Entscheide wie eine KI” in Kooperation von ProDaBi und inf-schule.de entstanden. Sie bietet eine Ergänzung zu den in ProDaBi entwickelten Lebensmittel-Datenkarten und der entsprechenden Unterrichtsreihe zu Entscheidungsbäumen.
Die Lernstrecke ist für Schüler:innen aufbereitet und hat folgenden Einführungstext: “In dieser Lernstrecke sollst du eine Künstliche Intelligenz (KI) erzeugen, die anhand der Nährwerte eines Lebensmittels entscheidet, ob es eher empfehlenswert oder eher nicht empfehlenswert ist. Dabei wirst du deine KI mit ausgewählten Nahrungsmitteln selbst trainieren, um damit im Anschluss für weitere Lebensmittel eine Entscheidungshilfe zu haben.”
Links:
Informationen über Maschinelles Lernen
Maschinelles Lernen ist ein weiter Bereich, der verschiedene Methoden und Lernalgorithmen für das automatische Lösen unterschiedlichsterer Aufgabentypen umfasst. Das verbindende Element zwischen allen Methoden die zum maschinelle Lernen gehören ist, dass sie auf Trainingsdaten beruhen. Wir konzentrieren uns auf die Unterart des überwachten Lernens, insbesondere auf Klassifikationsaufgaben, die mit Entscheidungsbäumen gelöst werden können.
Bei der Klassifikation geht es darum, Objekte oder Individuen einer Population mit (idealerweise) korrekten Labels in Bezug auf eine bestimmte Fragestellung zu versehen. In der Statistik ist eine Population eine Menge von ähnlichen Individuen, Objekten oder Ereignissen, die für eine bestimmte Frage oder statistische Untersuchung von Interesse sind. Typische Beispiele für Klassifikationsaufgaben sind die Zuordnung eines Patienten (Individuum) zu einer Diagnose (Etikett) oder die KLassifikation von E-Mails als “Spam” oder “kein Spam”. Die möglichen Labels stammen aus einer Label-Menge, je nachdem, ob man von einem binären Klassifikationsproblem (zwei mögliche Labels) oder einem Multiklassen-Klassifikationsproblem (eine endliche Menge von mehr als zwei Labels) spricht.
Die Aufgabe eines Lernalgorithmus besteht darin, einen Klassifikator zu erstellen, der für jedes beliebige Objekt in der Population ein Label vorhersagt. Um eine fundierte Vorhersage zu treffen, wird ein Objekt durch eine Reihe von Merkmalen repräsentiert, die als Vektor dargestellt werden. Da die Merkmale die Wahl des vorhergesagten Labels beeinflussen, werden sie als Prädiktorvariablen bezeichnet. Die Labels sind die Werte einer so genannten Zielvariable. Die Erstellung eines Klassifikators basiert auf Trainingsbeispielen, d. h. auf Objekten aus der Grundgesamtheit, von denen die Werte der Prädiktorvariablen und die korrekten Labels bekannt sind. Ein Satz von Trainingsbeispielen wird als Trainingsdaten bezeichnet. Als Maß für den Erfolg wird in der Praxis anhand von Testdaten die Fehlklassifikationsrate berechnet. Die Testdaten sind strukturell identisch mit den Trainingsdaten, wurden aber nicht zur Erstellung des Klassifikators verwendet.
Entscheidungsbäume werden algorithmisch aus Daten konstruiert, um als Klassifikatoren zu dienen. Besonders wenn der Baum nicht zu groß ist, macht die Verwendung einer hierarchischen Baumstruktur die Entscheidung sehr transparent und verständlich.
Informationen zum Nutri-Score
Ein Infoblatt zum Nutri-Score und der einfacheren Kategorisierung in der ProDaBi Unterrichtsreihe finden Sie hier: