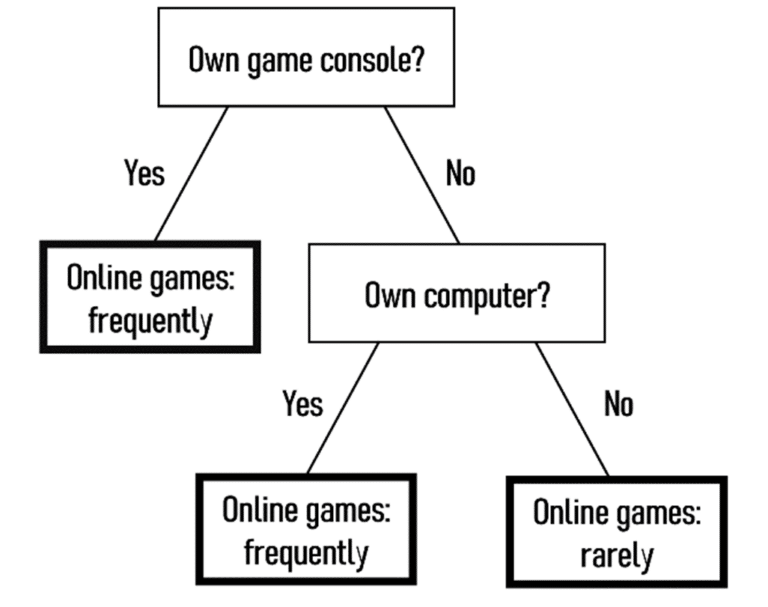
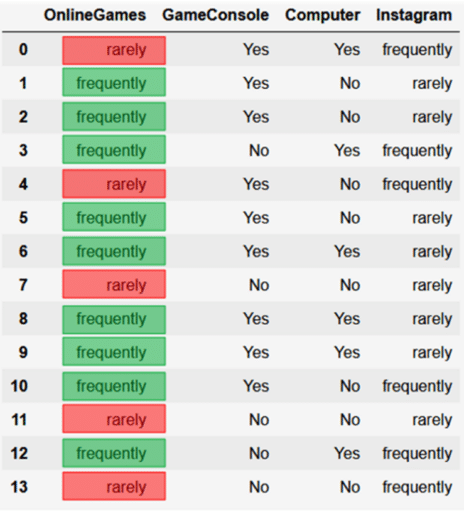
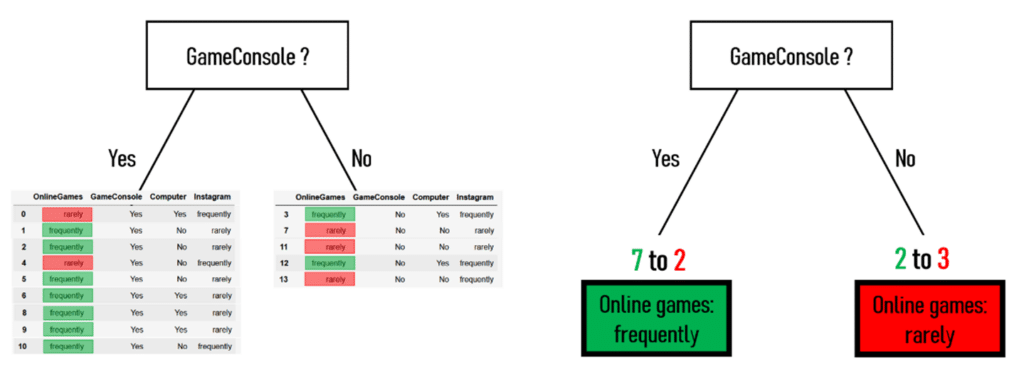
Basisfunktionen - Entscheidungsbäume mit arbor erstellen und interpretieren

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Maschine spielen - Entscheidungsbäume systematisch erstellen und dokumentieren
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Testen mit Testdaten - Entscheidungsbäume systematisch evaluieren
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Pruning - Entscheidungsbäume systematisch optimieren
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Einen eigenen Datensatz in CODAP importieren
Das Arbor Plugin für Entscheidungsbäume importieren
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Ein CODAP Dokument per Link teilen